
Thirty (yes, 30!!) years of OmniGroup.com, 100 Episodes of the Omni Show, AND the 5th anniversary of this podcast? We try to contain our excitement as we reminisce with Ken Case.
Thirty (yes, 30!!) years of OmniGroup.com, 100 Episodes of the Omni Show, AND the 5th anniversary of this podcast? We try to contain our excitement as we reminisce with Ken Case.
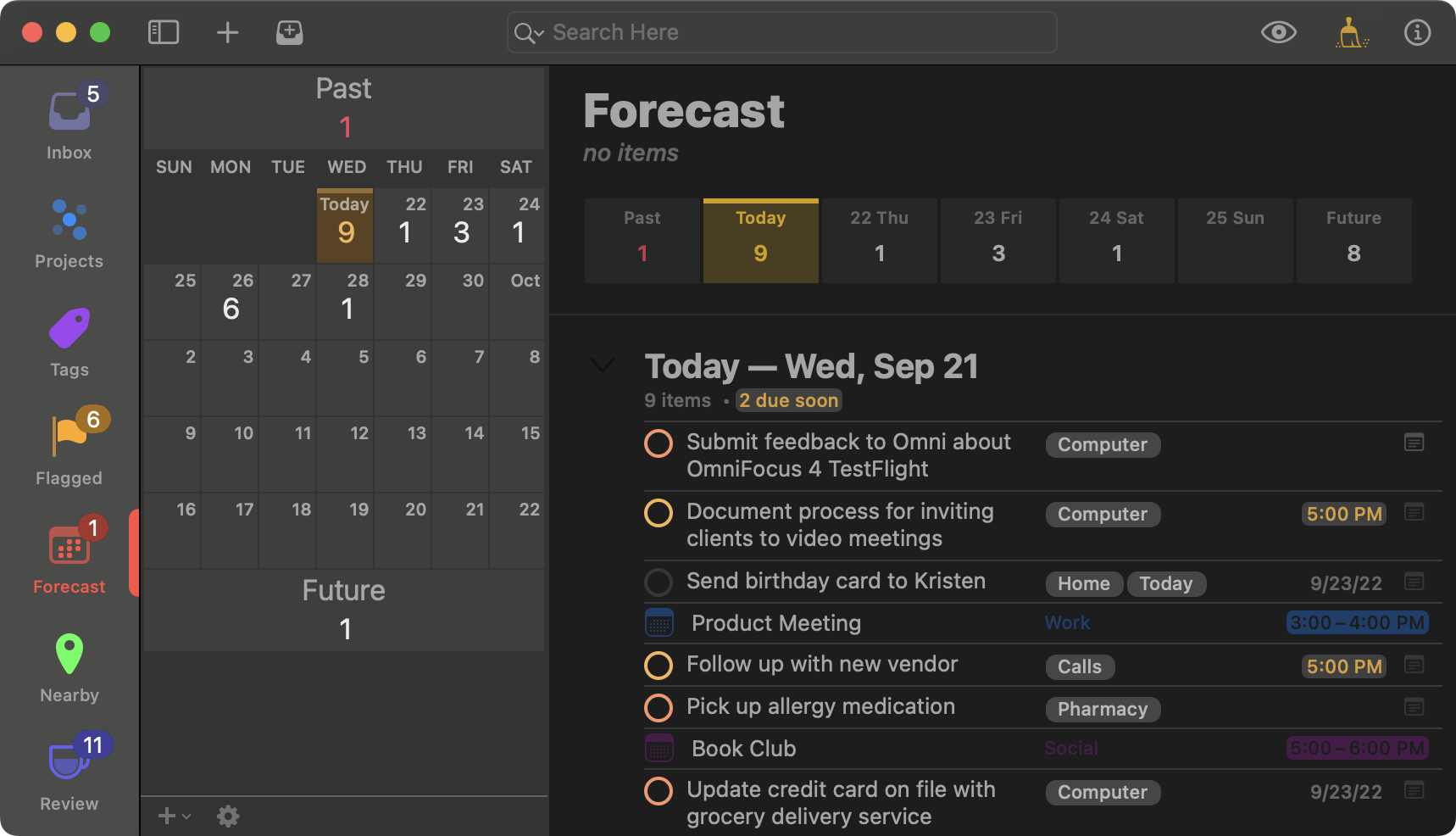
The OmniFocus team has been hard at work on OmniFocus 4, a major new version of OmniFocus for all platforms. Today, we are excited to announce some much anticipated news: OmniFocus 4 for Mac test builds are now available in TestFlight!
Our apps are ready for iOS 16, and we hope you enjoy it when it ships next week. Coincidentally, 30 years ago today was the day that NeXTSTEP 3.0 shipped and we registered omnigroup.com!

Today, we’re talking with Leah Ferguson, a Canadian designer who creates experiences in the digital and built environment through way-finding and information architecture.
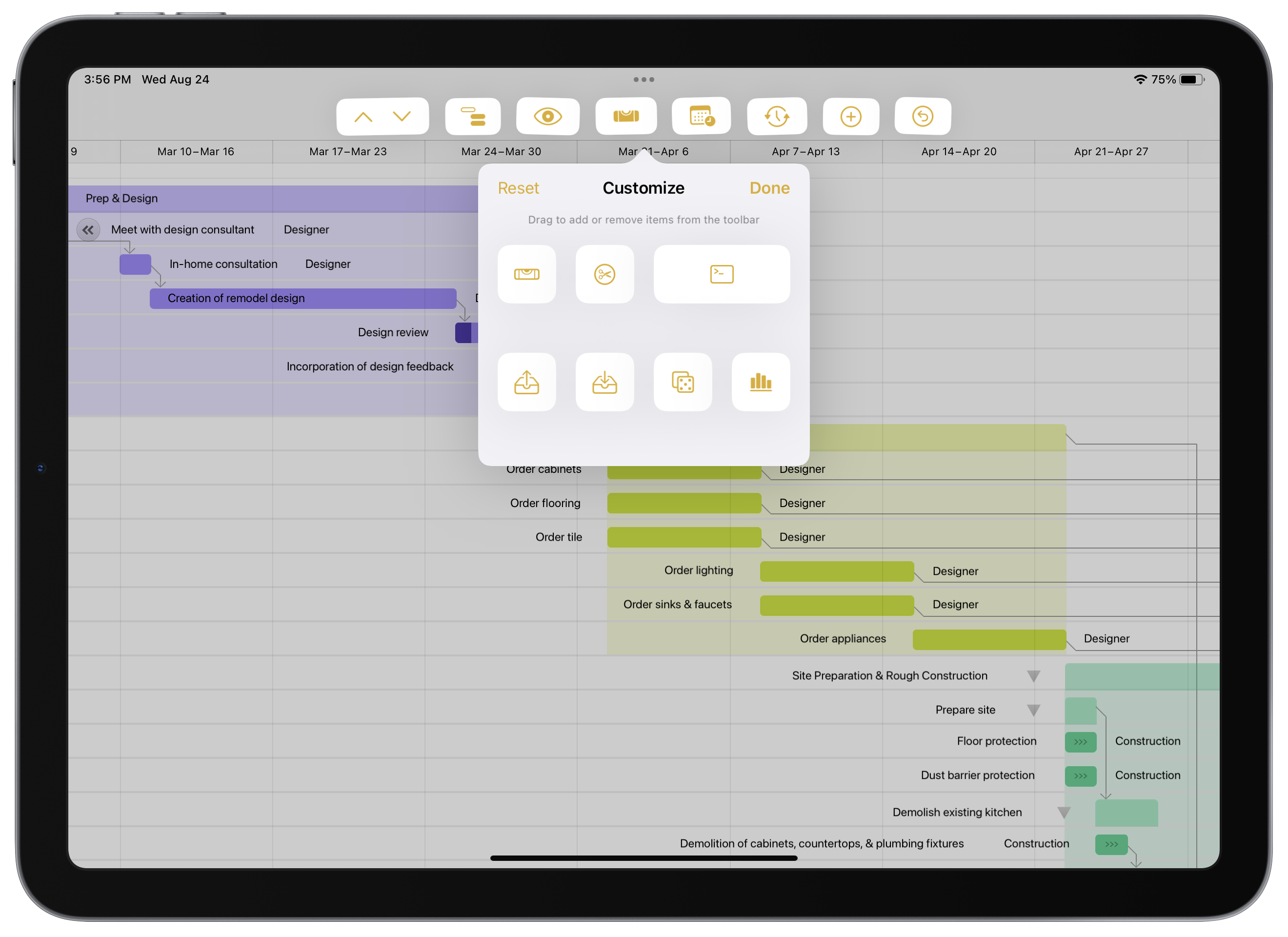
Updates to OmniGraffle, OmniOutliner, and OmniPlan include support for new toolbar functionality on iPads running iPadOS 16.

We've updated our online store so that there's no longer a distinction between team and personal licenses. You can purchase however many licenses you need—traditional up-front licenses or subscriptions—then use them yourself or share them with team members. We've reduced the number of choices each of you have to make when purchasing our software, while still providing flexibility for how you use purchased licenses.

Today, we’re joined by Professor Inger Mewborn (Director of Researcher Development at Australian National University) and Jason Downs (Deputy Director, Quality and Standards at La Trobe University). Collectively, they host a great productivity podcast called “On the Reg.”

Released today, OmniFocus 3.13 provides a wide range of improvements to Omni Automation---perhaps most notably adding support for Speech Synthesis, but also a number of other improvements as well.

Ken Case, CEO, joins the show to break down his post-WWDC 2022 Roadmap.
What’s the latest? What’s amazingly cool?
And — the annual question — just how much work will we be doing this summer?

One of the predictable sources of news affecting our plans is Apple's Worldwide Developer Conference, so each year we leave space in our schedule to jump into that firehose of information—and when we emerge, we update our plans and share what we've learned about changes that might affect our roadmap.
June 27, 2022
It's probably no surprise that writing software is a somewhat difficult task. There's an unfathomable amount of iteration and detective work that goes into creating a product that feels intuitive for the new user, yet familiar to the ardent fan. Surprisingly, the art of crafting effective software documentation demands some of the exact same iteration and detective skills. Inserting helpful guidance at just the right point in the user conversation (without over-explaining) can be a tricky dance.

On today’s show, we’re talking with Kaitlin Salzke. Kaitlin’s a tax accountant, mother, and computer science student who just happens to be in the middle of a big move (all while coding Omni Automation Plug-Ins for OmniFocus in her *spare* time!)

Today, we’re hanging out with Stephen Dolan. Stephen is the chief of staff at Tuple, a company that makes remote pair screen-sharing software for programmers / developers.

We’re honored to have Dr. Mark Hutchinson with us today. He’s the Director of the Arc Center for Excellence for Nano-Scale Biophotonics and the current president of Science and Technology Australia. He also happens to be an avid OmniFocus user!
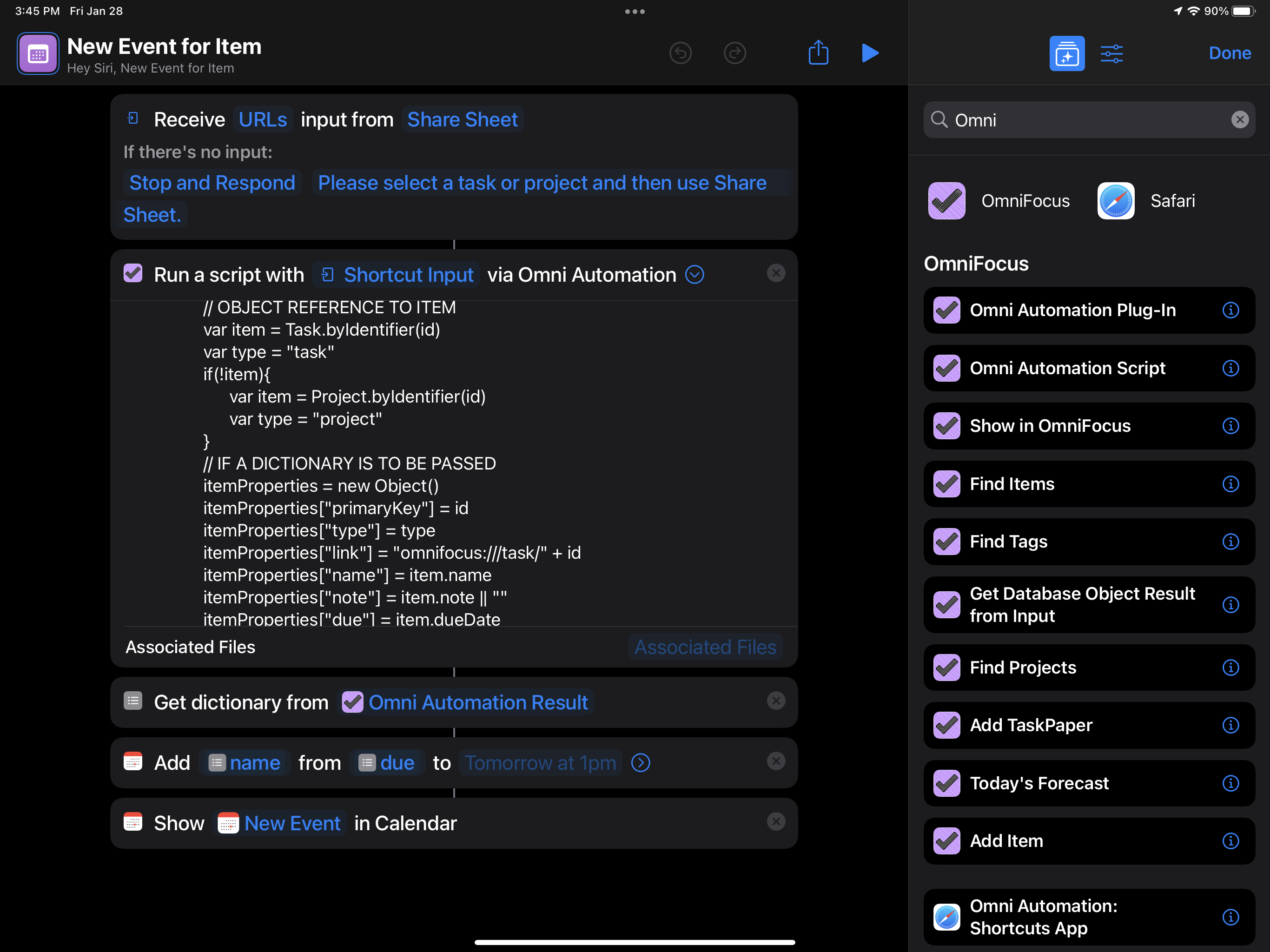
For anyone who uses any of our apps on an iPhone or an iPad, we're starting out the year with updates across the board. With these updates, Omni Automation in Shortcuts is available across all of our apps and on all platforms.

Today we're spending time with Dr. Amy J. Ko. She's a respected professor at the University of Washington Information School and an adjunct professor at the Paul G. Allen School of Computer Science and Engineering.

Today, we hang out with the CEO of the Omni Group, Ken Case. He talks us through all of the exciting details of the Omni 2022 Roadmap Blog Post.

Redesigning and rebuilding our apps based on the latest Apple technologies remains our current focus. This ongoing effort has now borne fruit with last year's OmniPlan 4 release, continues with the current OmniFocus 4 TestFlight, and—approaching over the horizon—is expected to lead to an incredible update to OmniGraffle.
January 31, 2022
Today we talk to Joe Buhlig. As an "analog mind in a digital world", Joe's unique method of using both digital and paper tools resonates with his listeners in a refreshing way.

Today we talk to Naomi Pearce, media relations representative for the Omni Group. This show - and the timing of the show itself - dives into what sort of stress-free goodness can show up for everyday folks who use powerful software.
© 1994–2026 The Omni Group; Apple, MacBook, the Apple logo, iPad, iPhone, Apple Watch, and App Store are trademarks of Apple Inc., registered in the U.S. and other countries and regions. Apple Vision Pro is a trademark of Apple Inc.