
Ken Case was invited onto the 58Keys podcast to discuss how he uses OmniOutliner for writing with William Gallagher.
Ken Case was invited onto the 58Keys podcast to discuss how he uses OmniOutliner for writing with William Gallagher.
Ken was invited on The Changelog podcast in the wake of Apple’s “One More Thing” event.

Our world is constantly changing, and each year we have to be prepared to adjust our plans. If we want our products to stay relevant for another twenty years, adopting the latest technologies is the right move.
Understanding the differences between a wireframe and a prototype will help you determine which one best suits your needs during the creative process.

Team subscriptions are a great new purchasing option that dramatically simplifies licensing for teams—available now in OmniPlan 3.14 for Mac and OmniPlan 3.13 for iOS.
OmniFocus 2 uses view-based table views and Auto Layout for its sidebar and main outlines. In adding Custom Columns layout we had several problems to solve.
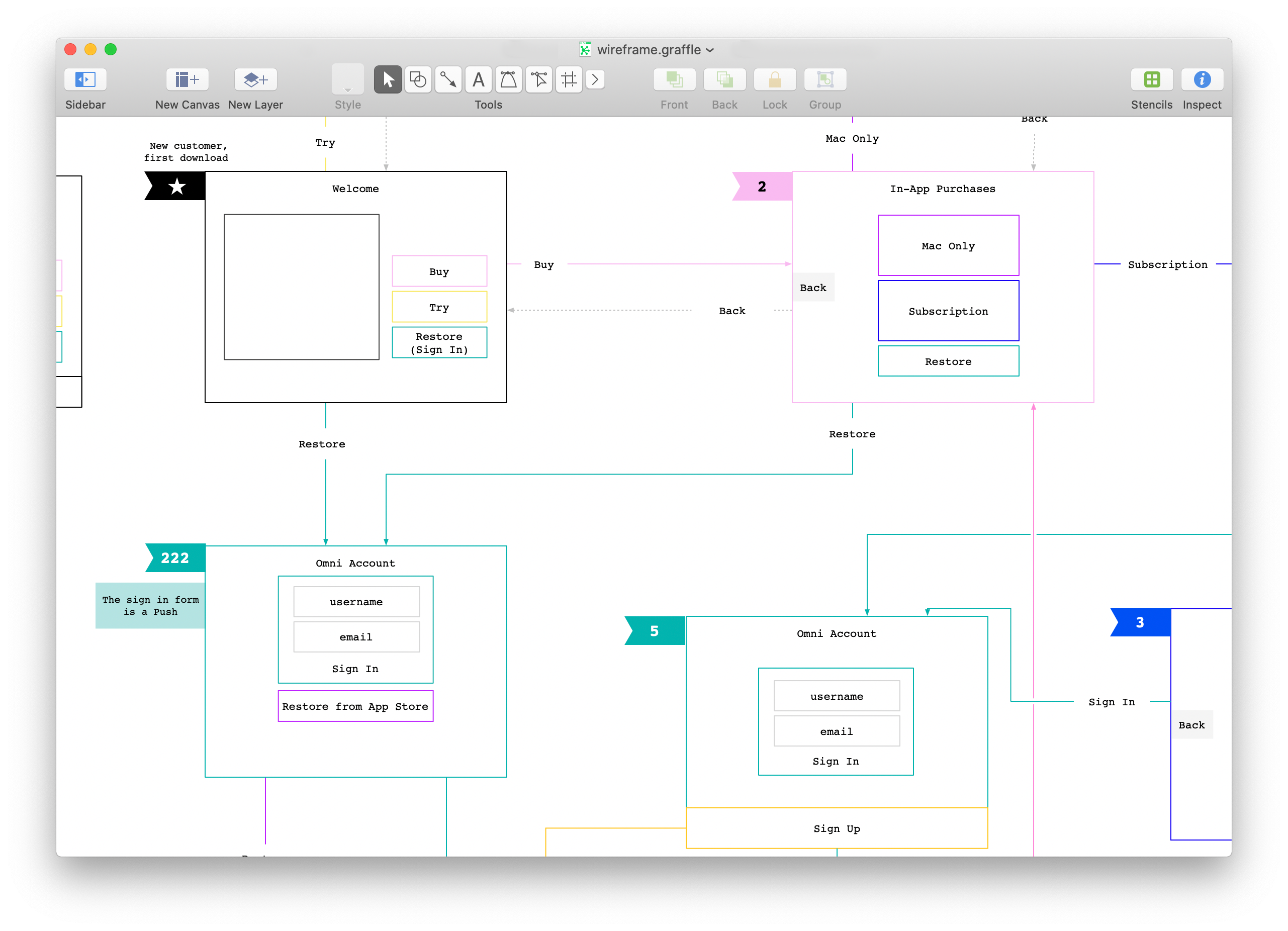
Version 2.3 of OmniFocus for Mac brings two new options for how to view your tasks and projects. This is the design story.
As mentioned earlier, much of Omni Sync Server is built atop FreeBSD, and the push provider is no exception.
Omni's push provider needs to do a fair bit of preprocessing and other work for every notification it prepares to send. In the current provider, we consider each notification.
Now that we've converted our notification data into a format that's suitable for sending to Apple, our fledgling push provider needs a connection into APNs in order to send that data.
Ideally, blur and vibrancy add a subtle liveliness to the UI. Unfortunately, as we recently discovered, they can also make your text unreadable.
Always think carefully before adding ATS exceptions.
Lately Brent has been fixing crashes in the Mac versions of OmniFocus and OmniOutliner. Some themes emerged.
After researching languages and choosing Go to implement a push provider for OmniFocus, we needed to get started writing code.
I’ve been on crash-fix-duty for a while with the Mac version of [OmniFocus](https://www.omnigroup.com/omnifocus), and just as I was climbing out and starting work on a new feature, I got sidetracked into working on performance.
Here at the Omni Group, we have a long history of writing code in Objective-C. However, our attention turned to building a provider that could handle the large existing OmniFocus customer base, along with the specific traffic patterns the app generates.
We’re starting a developer blog. You’re already reading it!
© 1994–2026 The Omni Group; Apple, MacBook, the Apple logo, iPad, iPhone, Apple Watch, and App Store are trademarks of Apple Inc., registered in the U.S. and other countries and regions. Apple Vision Pro is a trademark of Apple Inc.