
Implementing Custom Columns Layout in OmniFocus for Mac
by Curt Clifton on December 10, 2015By William Van Hecke and Curt Clifton
In our previous post we discussed the design of Custom Columns layout for OmniFocus for Mac. In particular, we wanted to add this feature while keeping the improved approachability that is a hallmark of OmniFocus 2.
In this post, we’ll discuss how we implemented this design in our existing app.
Implementation
OmniFocus 2 uses view-based table views and Auto Layout for its sidebar and main outlines. In adding Custom Columns layout we had several problems to solve.
- What class should be responsible for determining the current layout? Recall that the current layout is a function of the user’s app-wide default settings, whether they have upgraded to Pro, the current perspective, and whether that perspective has layout customizations.
- If we’re using Custom Columns layout, which columns should be shown?
- How wide should each column be given the current window width?
- How do we position the fields for each column?
- How do we decide when to elide columns because the window is too narrow or the hierarchy indentation is too deep?
Choosing the Current Layout
Here’s a diagram showing the structure of controllers and views in an OmniFocus window before we added Custom Columns layout.
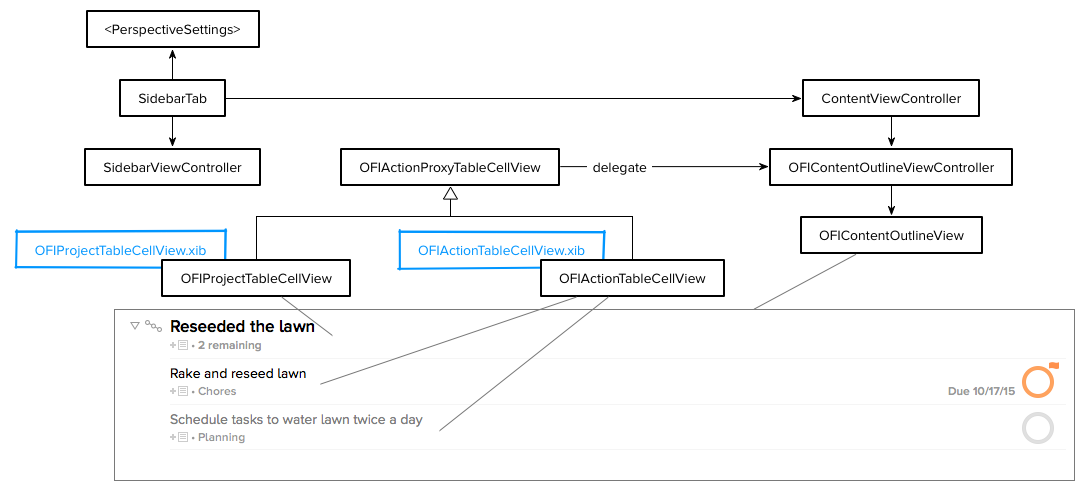
When switching tabs, the selected sidebar tab extracts the layout mode and other settings from the tab’s perspective. It then uses our window state restoration machinery to pass these settings down to the ContentViewController. The ContentViewController forwards the layout settings to the OFIContentOutlineViewController.
The outline view controller considers this per-perspective layout setting, the current Pro upgrade or trial status, and the value of the app-wide layout preference to determine the current layout mode. For each row in the main outline, the outline view controller uses the corresponding model object along with the current layout mode to vend the correct table cell view.
Sharing Code for Table Cell Views
For Custom Columns layout we needed to use different table cell views, but wanted to retain as much of the existing, working code as possible. As the figure above shows, both OFIProjectTableCellView and OFIActionTableCellView are backed by .xib files and have a common superclass, OFIActionProxyTableCellView. We wanted to add two more leaf nodes and .xibs for Custom Columns layout: OFIProjectColumnarTableCellView and OFIActionColumnarTableCellView. These classes needed to share some behavior with each other, but also needed to share some behavior with their corresponding Fluid variant. For example, both OFIActionTableCellView and OFIActionColumnarTableCellView needed to manage their status circles. This is a classic example of the diamond inheritance problem.
Since Objective-C (and Swift) don’t have multiple inheritance, we chose to solve this diamond inheritance by introducing assistant classes for the action and project table cell views. Here’s a diagram showing that design.
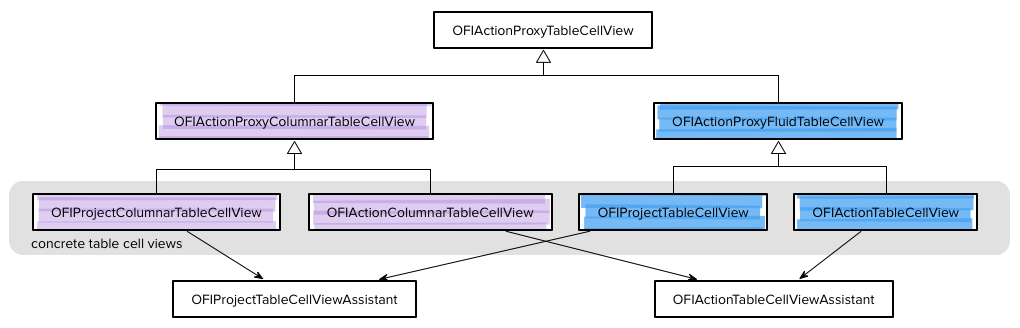
Shared code for the Custom Columns table cell views lives in OFIActionProxyColumnarTableCellView as shown on the left side of the diagram. The existing shared code for regular table cell views moved to OFIActionProxyFluidTableCell, shown on the right side of the diagram. The shared code across all these table cell views, primarily for managing notes, lives in OFIActionProxyTableCellView at the top of the diagram. Finally, the two assistant classes, shown at the bottom of the diagram, do the chores that are shared by all project rows (like displaying action counts) and by all action rows (like updating status circles). This design works well. The concrete table cell views have very little code. That code is primarily devoted to forwarding messages to the appropriate assistant. The .xib for each concrete table cell view handles instantiating the assistant at the same time the table cell view itself is instantiated.
With this code sharing problem solved, the basic structure when using Custom Columns layout is shown in the diagram below. The highlights show the changes from the original Fluid layout.
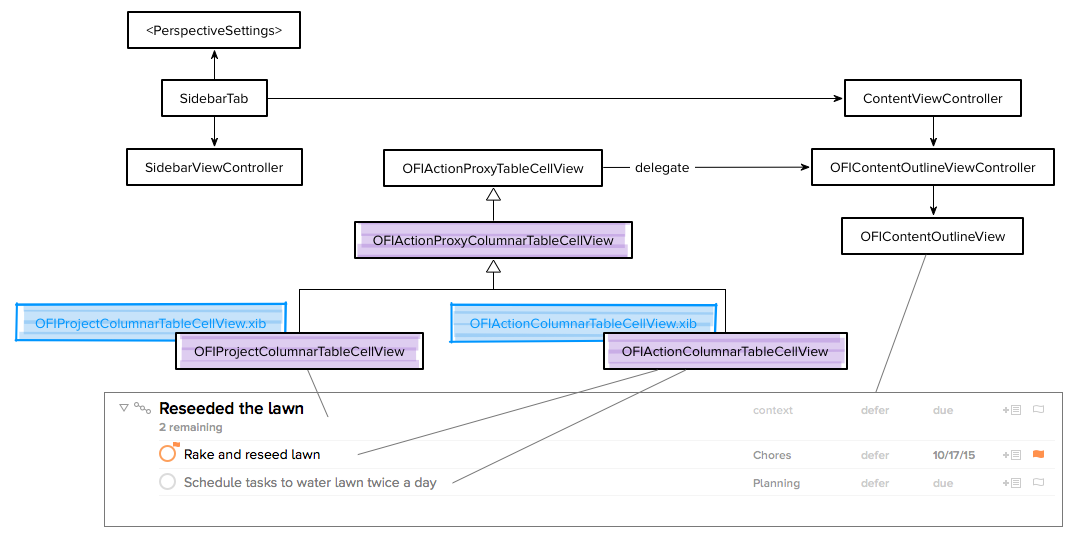
Sharing Column Info with Table Cell views
Once we had the correct table cell views for Custom Columns layout, the next challenge was letting cells know which columns should be visible. Recall that the OFIContentOutlineViewController knows about the current layout settings. Conveniently, our table cell views already had a delegate pointer to the outline view controller. The outline view controller implemented an OFITableCellViewDelegate protocol. To get column information, we add a new method to this protocol:
- (OFIColumnLayoutManager *)columnLayoutManagerForCellView:(OFITableCellView *)cellView;
Our table cell views call this delegate method. The outline view controller, as the delegate, decides which columns should be visible and instantiates an OFIColumnLayoutManager. This column layout manager is immutable and exposes all the information about columns necessary for the table cell view to decide which columns to show and where to position them. Here’s what the header looks like:
/// Instances of this class are immutable. We rely on that fact to do identity comparisons.
@interface OFIColumnLayoutManager : NSObject
- (instancetype)init NS_UNAVAILABLE;
- (instancetype)initWithColumnSpecifications:(NSArray <OFIColumnSpecification *> *)columnSpecifications NS_DESIGNATED_INITIALIZER;
// Width management
@property (nonatomic, readonly) CGFloat minimumTitleWidth;
@property (nonatomic, readonly) CGFloat maximumTitleWidth;
@property (nonatomic, readonly) CGFloat minimumMetadataColumnsWidth;
@property (nonatomic, readonly) CGFloat maximumMetadataColumnsWidth;
@property (nonatomic, readonly) BOOL areAllMetadataColumnsFixedWidth;
@property (nonatomic, readonly) NSArray <NSNumber *> *minimumColumnWidths;
/// Returns an array of NSNumbers, the CGFloat of which gives the column width.
- (NSArray *)columnsWidthsForTotalWidth:(CGFloat)totalWidth;
/// Calculates the multiplier and constant for a constraint relating the width of the title text field to the width of all the other columns combined.
/// - Parameter outMultiplier: must be non-NULL
/// - Parameter outConstant: must be non-NULL
/// - Returns: whether the out parameters were set
- (BOOL)titleWidthToOtherColumnsWidthConstraintMultiplier:(CGFloat *)outMultiplier constant:(CGFloat *)outConstant;
// Metadata column metadata
@property (nonatomic, readonly) NSInteger numberOfColumns;
@property (nonatomic, readonly) NSArray <NSNumber *> *columnKinds;
@end
We instantiate a column layout manager with an array of OFIColumnSpecification instances. These encapsulate the column kind and its minimum and maximum width.
Now we have enough information in the table cell view to layout out the columns. How should we do that?
Calculating Column Widths
Recall our goals:
- Automatically choose the width for each column.
- Resize variable-width columns proportionally with the width of the window.
- Make indented child actions steal space from the title column until they reach a minimum width.
- Beyond that, omit columns from left to right so that the existing columns remain aligned.
The graph below, which lived on Curt’s whiteboard for the summer, relates our desired column width to the table cell view width.
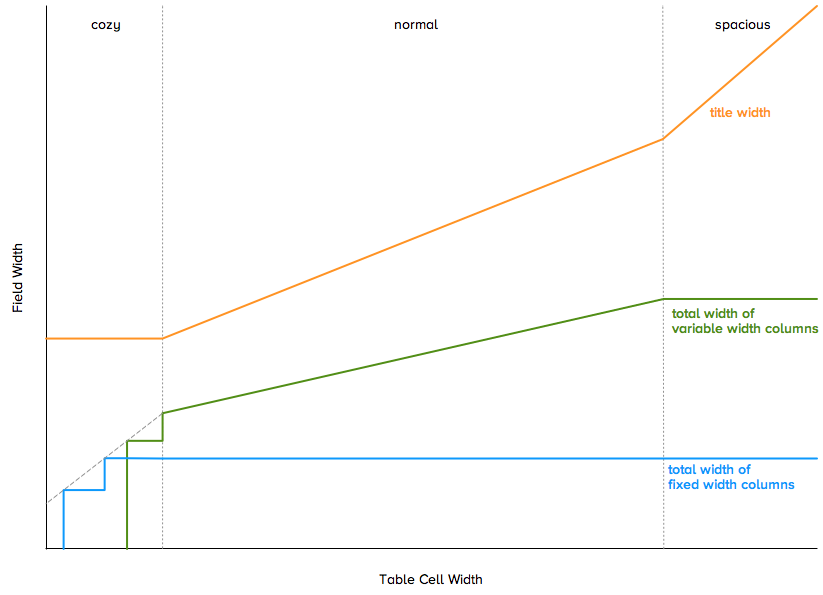
The graph shows three regions. Let’s consider these right to left, as we’d pass through them if you were making your OmniFocus window narrower. Here’s an example row laid out for the various regions.
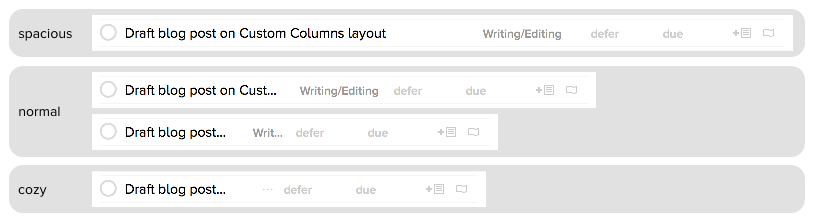
At the window’s widest, we’re in the spacious region on the right. When a table cell view is wide enough to be in this region, resizing the window directly resizes the title column. All the variable-width columns are at their maximum widths. And, of course, all the fixed-width columns are at their fixed widths.
As we make the window narrower, we enter into the normal region in the middle. Here all the fixed-width columns remain at their fixed widths and we allocate the remaining width proportionally between the item titles and the variable-width columns.
As we make the window narrower still, we enter the cozy region on the left. (We can also get cozy table cell views when you indent tasks inside action groups.) In this region all the columns have reached their minimum widths, so we have no choice but to drop columns. The stair steps in the graph represent the columns being removed.
Our existing table cell views all use Auto Layout. It’s an important part of our mechanism for handling variable-height rows that wrap the title text. We don’t want to lose that capability. On the other hand, in the cozy region, our column widths are non-linear; there’s a stepping down of widths as we elide columns. Auto Layout doesn’t handle non-linearity.
Cocoa’s solution for these cases is NSStackView, which allows you to set priorities on subviews and have them automatically removed as needed. NSStackView is great for many use cases. Unfortunately, we’ve found that it doesn’t yet perform adequately when used in table cell views, many dozens of which can be laying out at once (for example, while you resize a window).
We solved this problem by using a mix of Auto Layout and manual layout.
Mixing Auto Layout and Manual Layout
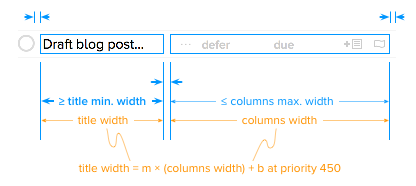
Our strategy is to use Auto Layout at the top level inside the table cell views, but to put all the column subviews inside a single OFIMetadataColumnsView that manually positions the columns. The title view and columns view are positioned and sized using Auto Layout. This figure shows the horizontal constraints that we use to do that.
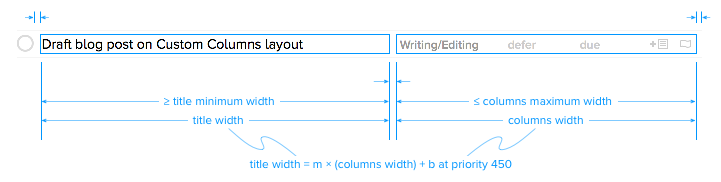
Going from the top of the figure down, we have fixed constraints setting the left edge of the title view, the right edge of the columns view, and the space between them. Next we have a constraint that sets the minimum width of the title field, followed by one that sets the maximum width of the columns. Finally, we have a low priority constraint relating the width of the title view to the width of the columns view. The priority on this ratio constraint is less than the OS-provided window resizing priorities. So, the window can be resized in a way that breaks this ratio constraint. This priority scheme allows different constraints to be active at different table cell widths.
In the spacious region, the maximum width constraint on the metadata columns view is active. The low priority ratio constraint is violated, which is why it’s low priority. Autolayout allocates all extra width to the title view as shown below.
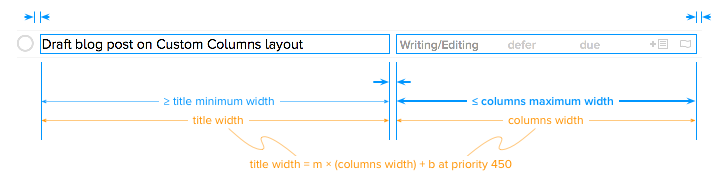
In the normal region, as shown below, the constraint that relates title view width to column view width is active.
The constants for this ratio constraint are calculated based on the minimum and maximum widths of all the columns using a bit of algebra.
(For the curious:
max. title width = m * (max. variable width columns width + fixed columns width) + b
and
min. title width = m * (min. variable width columns width + fixed columns width) + b
Solve for m and b, then plug in the current values for all the other terms from the column layout manager. For child actions, we then adjust b to account for indentation.)
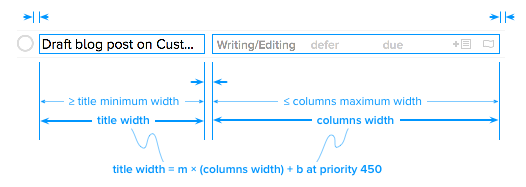
Finally, in the cozy region, the minimum width contraint on the title view becomes active. The ratio constraint is violated once again. Auto Layout steals space from the columns view to maintain the width of the title view.
Manual Column Layout
During a layout pass, the Auto Layout system sets the frame of the columns view, then calls the layout method on OFIMetadataColumnsView. OFIMetadataColumnsView has a delegate pointer that references its host table cell view. We use that to get the information we need to position the column subviews.
First, we ask the delegate to provide an array of views, one for each column you’ve asked us to display. We install these as the subviews of the OFIMetadataColumnsView.
Next we get the desired and minimum width for each column from the delegate. We loop through the columns from right to left. For each we check whether there is enough space to render the column subview. If so, we set the frame of the subview to the desired size. In cases where we’re indenting child actions, we may not have room to render the column subview at its desired size. As long as there is enough space for at least the minimum size, we’ll still show it.
Finally, if we run out of room before positioning all the subviews, then we hide the remaining column subviews and add a mid-elipsis, ⋯, to indicate that we’re eliding some columns.
Conclusion
This implementation is not simple, but we think the experience that we’re providing is. You decide which information you would like to see. When you need more or less space, it should be as easy as resizing the window; OmniFocus and your Mac do the work to display that information in the space given, letting you focus on your own tasks.
 When you have to manage column widths yourself, you can end up with awkward wrapping and ugly holes in your layout.
When you have to manage column widths yourself, you can end up with awkward wrapping and ugly holes in your layout. OmniFocus 2 Fluid is more space-efficient than OmniFocus 1 if you use a narrow window.
OmniFocus 2 Fluid is more space-efficient than OmniFocus 1 if you use a narrow window. With wide windows, the Fluid layout is less dense. The new Custom Columns layout makes more efficient use of the width, with plenty of room for any extra columns you may care to add.
With wide windows, the Fluid layout is less dense. The new Custom Columns layout makes more efficient use of the width, with plenty of room for any extra columns you may care to add.